字幕乱码常见,却非不可解。本文聚焦中文字字幕在线乱码的成因、修改思路及实战排错技巧,力求从问题定位到快速修复提供一套可落地的方法,帮助编辑与运营在实际场景中尽快恢复可读文本。
第一步是识别编码与文件格式。常见的字幕格式包括 .srt、.ass、.ssa 等。不同格式对编码的敏感度各有差异,若文本显示为诡异字符或方块,往往与编码不匹配有关。先确认字幕文件的保存编码,例如 UTF-8、GBK、GB2312、UTF-16 等,并检查是否有字节序标记 BOM。
接着要判断场景类型。若大段中文直接变成无意义符号,常是原始编码被错误解读;若显示为分散的字形错乱,可能是字体缺字或字体替代问题;若时间码跳动或文本错位,播放器对编码头部或字幕流的处理出现偏差。
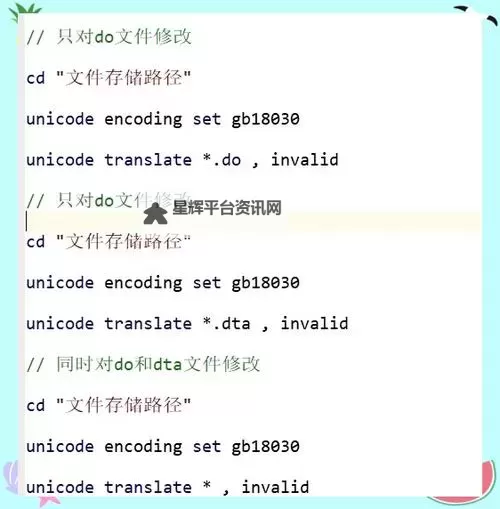
修复技巧之一是进行编码转换。以 Linux 或 macOS 为例,可用命令行将文件从原编码转为 UTF-8,如 iconv -f 原编码 -t utf-8 input.srt > output.srt。若不确定原编码,可先用检测工具估算再转换,避免反向转回失败。转换后再用文本编辑器打开,确保文本可读。
另一条路径是调整显示端的设置,确保使用支持中文的字体且启用字体回退。某些播放器对中文字体的缺失极为敏感,若方块依旧,需在系统层面安装常用简体中文字体并保持默认字体链的顺畅。
排错流程可以按三步走。先确认字幕流的编码头,必要时用十六进制查看 BOM;再检测网页或播放器的 Content-Type 是否声明了正确的 charset;最后对照原文看看是否有错别字或剪切错误导致的乱码产生。
实战中的技巧包括建立一个对照集:同一字幕在不同编码下的表现截屏、记录修改前后的差异、逐步记录每次转换的结果。遇到彩色条或时码错位时,往往与时间码的格式或回车符有关,可尝试将回车符统一为 Windows CRLF 或 Unix LF。
最后的要点是保持过程的可追踪性。对每次改动都做注释,保留原始文件备份,避免重复劳动。在线字幕工作需关注编码、字体和传输三点,少量变化常常带来显著提升。